
## 序: 术语明确
- 字(word)
是用于表示其自然的数据单位,也叫
machine word。字是电脑用来一次性处理事务的一个固定长度。
- 字长
一个字的位数(即字长)。
现代电脑的字长通常为16、32、64位。(一般N位系统的字长是
N/8字节。)电脑中大多数寄存器的大小是一个字长。CPU和内存之间的数据传送单位也通常是一个字长。还有而内存中用于指明一个存储位置的地址也经常是以字长为单位。
## 1. 为什么要内存对齐
简单来说,操作系统的cpu不是一个字节一个字节访问内存的,是按2,4,8这样的字长来访问的。
所以当处理器从存储器子系统读取数据至寄存器,或者,写寄存器数据到存储器,传送的数据长度通常是字长。
如32位系统访问粒度是4字节(bytes),64位系统的是8字节。
当被访问的数据长度为
n字节且该数据地址为n字节对齐,那么操作系统就可以一次定位到数据,这样会更加高效。无需多次读取、处理对齐运算等额外操作。
## 2. 内存对齐,对于性能的提升
package test
import (
"testing"
"unsafe"
)
var ptrSize uintptr
func init() {
ptrSize = unsafe.Sizeof(uintptr(1))
}
type SType struct {
b [32]byte
}
func BenchmarkUnAligned(b *testing.B) {
x := SType{}
address := unsafe.Pointer(&x.b[9])
if uintptr(address)%ptrSize == 0 {
b.Error("not UnAligned Address")
}
tmp := (*int64)(address)
b.ResetTimer()
for i := 0; i < b.N; i++ {
*tmp = int64(i)
}
}
func BenchmarkAligned(b *testing.B) {
x := SType{}
address := uintptr(unsafe.Pointer(&x.b))
if address%ptrSize != 0 {
b.Error("not Aligned Address")
}
tmp := (*int64)(unsafe.Pointer(address))
b.ResetTimer()
for i := 0; i < b.N; i++ {
*tmp = int64(i)
}
}
执行
go test -gcflags=‘-N -l’ ./11_test.go -bench . -count 3
output:
goos: darwin goarch: amd64 BenchmarkUnAligned-12 614625067 2.04 ns/op BenchmarkUnAligned-12 518480124 1.94 ns/op BenchmarkUnAligned-12 602900706 2.02 ns/op BenchmarkAligned-12 682062852 1.77 ns/op BenchmarkAligned-12 684985354 1.76 ns/op BenchmarkAligned-12 690433512 1.76 ns/op PASS ok command-line-arguments 8.294s
### 由此可以得出,在内存不对齐(内存地址不对齐)情况下,处理器修改数据将要访问两块内存块,而产生额外的开销
## 3. 内存数据结构对齐图解
### 3.1 基本的数据结构内存占用
| type | size in bytes | | :——————————– | :———— | | byte, uint8, int8 | 1 | | uint16, int16 | 2 | | uint32, int32, float32 | 4 | | uint64, int64, float64, complex64 | 8 | | complex128 | 16 |
###
### 3.2 内存对齐工具推荐
#layout
go get github.com/ajstarks/svgo/structlayout-svg //将json转化成图形
go get -u honnef.co/go/tools
go install honnef.co/go/tools/cmd/structlayout
go install honnef.co/go/tools/cmd/structlayout-pretty
#optmize
go install honnef.co/go/tools/cmd/structlayout-optmize
###
### 3.3 举例
// /Users/eric/GoProject/temp_test/test/ag/12.go
type Ag struct {
arr [2]int8
bl bool
sl []int16
ptr *int64
st struct {
str string
}
m map[string]int64
i interface{}
}
执行
structlayout -json ./test/ag Ag |structlayout-svg -t ‘align-gurantee’ > ag.svg
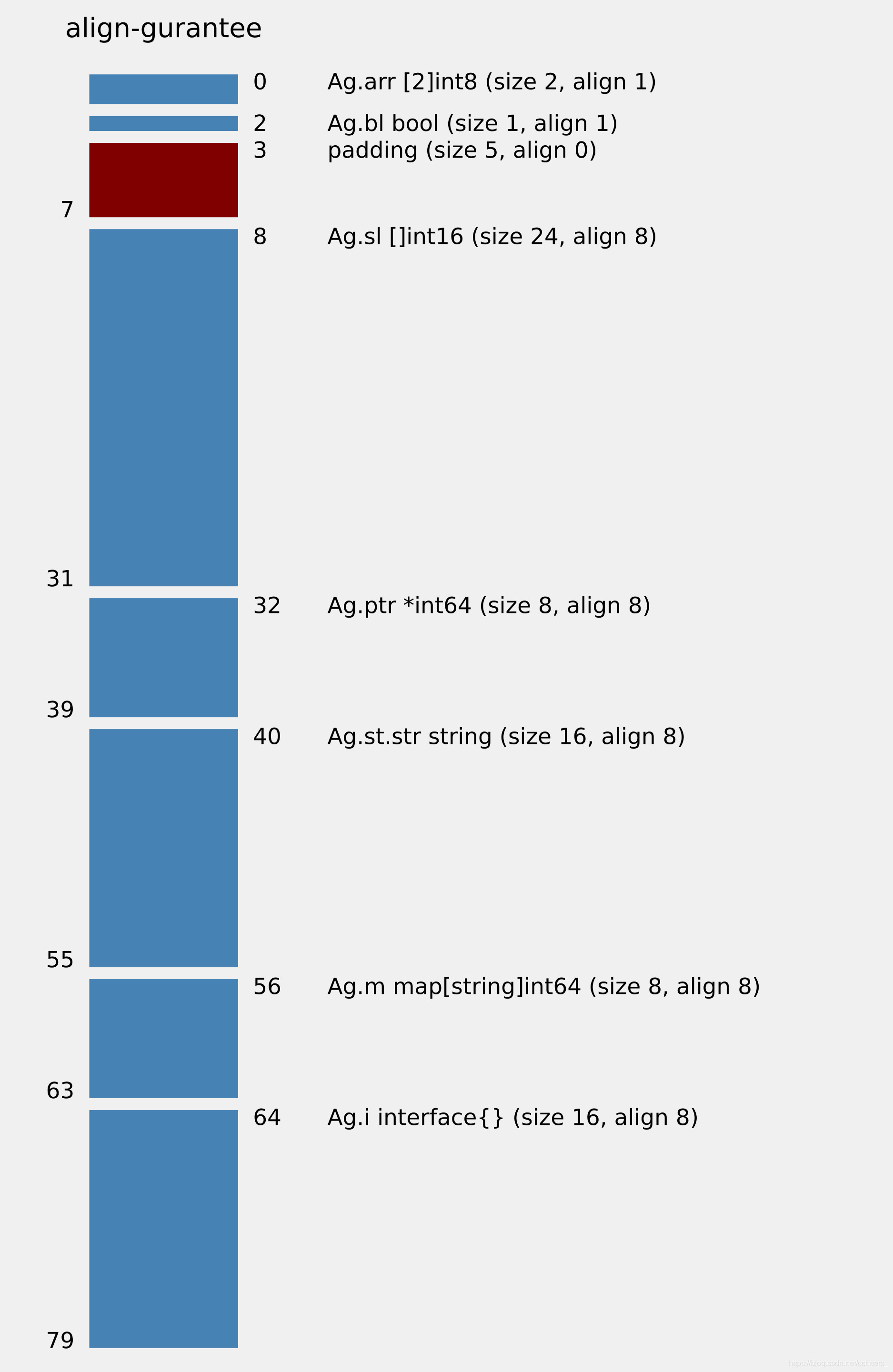
由图可知
###
### 3.4 数据结构对齐
// 注意 : 其中 int 会根据系统的环境 自动选择是 8 byte 还是 4 byte
// reflect/value.go
// StringHeader is the runtime representation of a string.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type StringHeader struct {
Data uintptr // 8 byte
Len int // 8 byte
}// total 16 byte
// SliceHeader is the runtime representation of a slice.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type SliceHeader struct {
Data uintptr // 8 byte
Len int // 8 byte
Cap int // 8 byte
}// total 24 byte
// runtime/map.go
// A header for a Go map.
// map 虽然内部结构较为复杂 但是 实际上 map 被返回的仅仅是一个指向 hmap 这个结构体的指针 所以长度为 8 byte
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
// runtime/runtime2.go
type iface struct {
tab *itab // 8 byte
data unsafe.Pointer // 8 byte
}// total 16 byte
type eface struct {
_type *_type // 8 byte
data unsafe.Pointer // 8 byte
}// total 16 byte
### 3.5 特例(Final Zero Field)
import (
"fmt"
"unsafe"
)
type T1 struct {
a struct{}
x int64
}
type T2 struct {
x int64
a struct{}
}
func main() {
a1 := T1{}
a2 := T2{}
fmt.Printf("zero size struct of T1 is %d , T2 (as final filed) size :%d",
unsafe.Sizeof(a1),
unsafe.Sizeof(a2),
)
}
output
zero size struct of T1 is 8 , T2 (as final filed) size :16
T2 of 64bit system :16 byte
T2 of 32bit system :12 byte
#### 原因:
在golang在结构体的最后一个field出现zero大小的byte时,会自动padding对齐
### 3.6 重排优化(粗暴方式-按对齐值的递减来重排成员)
通过优化成员顺序可以节省结构体所占用的内存
type MakeMeBetter struct {
i16 int16
i64 int64
i8 int8
i32 int32
ptr *string
b bool
}
// $ structlayout -json ./ MakeMeBetter |structlayout-optimize -r
//output :
//MakeMeBetter.i64 int64: 0-8 (size 8, align 8)
//MakeMeBetter.ptr *string: 8-16 (size 8, align 8)
//MakeMeBetter.i32 int32: 16-20 (size 4, align 4)
//MakeMeBetter.i16 int16: 20-22 (size 2, align 2)
//MakeMeBetter.i8 int8: 22-23 (size 1, align 1)
//MakeMeBetter.b bool: 23-24 (size 1, align 1)
优化前
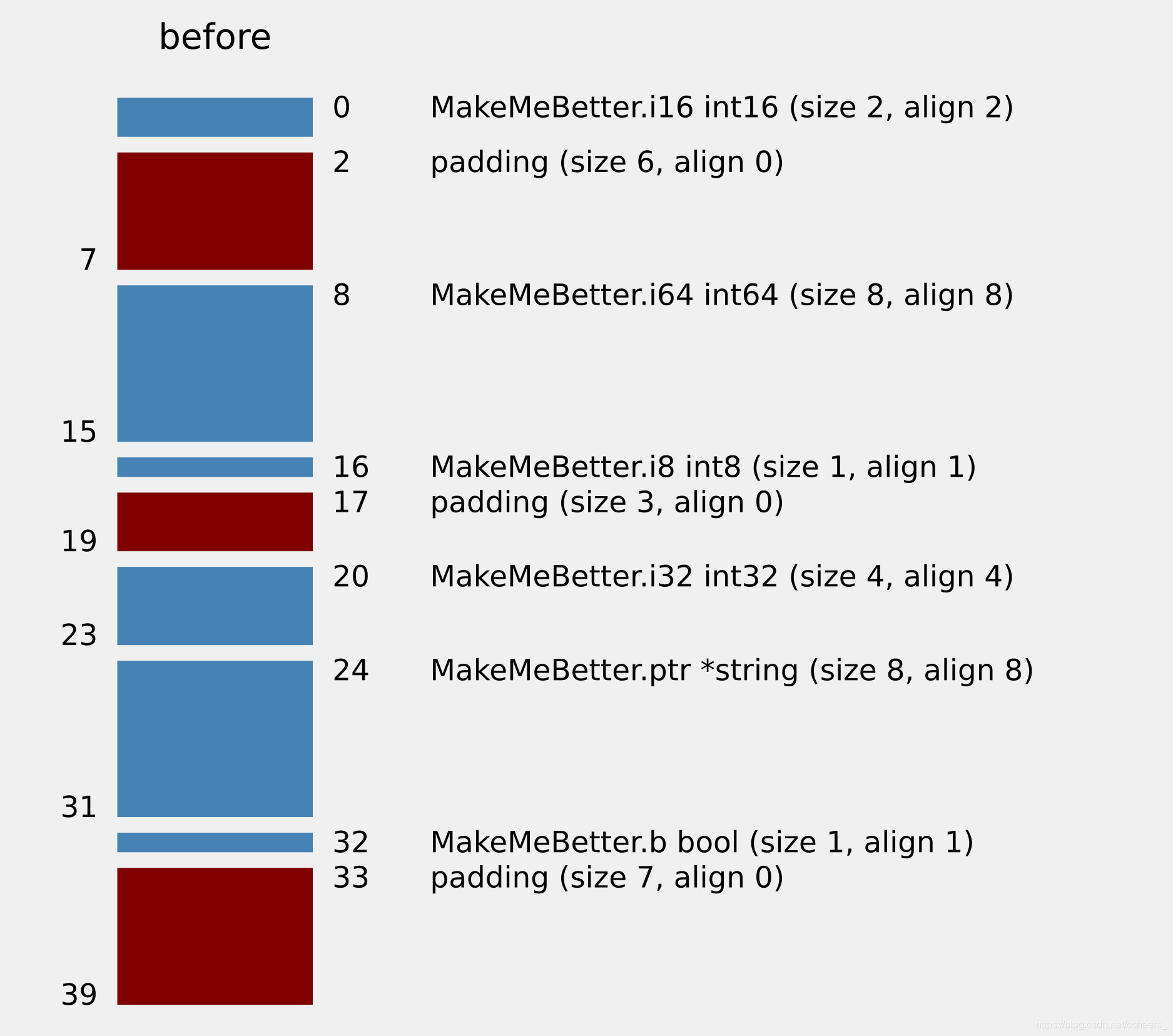
优化后

## 4. 内存地址对齐
计算机结构可能会要求内存地址对齐;也就是说,一个变量的地址是一个因子的倍数,也就是该变量的类型对齐值。
函数 Alignof 接受一个表示任何类型变量的表达式作为参数,并以字节为单位返回变量(类型)的对齐值。
对于变量 x:
uintptr(unsafe.Pointer(&x)) % unsafe.Alignof(x) == 0
### 内存不对齐原子操作int64而在32位系统报错:
x := SType{}
for i := range x.b {
fmt.Println(i, uintptr(unsafe.Pointer(&x.b[i])))
}
a := (*uint64)(unsafe.Pointer(&x.b[9]))
fmt.Printf("地址值:%d\n", uintptr(unsafe.Pointer(a)))
fmt.Printf("地址值除以8的余数:%d\n", uintptr(unsafe.Pointer(a))%8)
fmt.Printf("原子操作结果:%d\n", atomic.AddUint64(a, math.MaxUint64))
fmt.Println(atomic.LoadUint64(a))
### //Output:
地址值:405799145 地址值除以8的余数:1 panic: runtime error: invalid memory address or nil pointer dereference [signal 0xb code=0x1 addr=0x1 pc=0x8081aac]
goroutine 16 [running]: runtime.panic(0x80e0080, 0x814add3) /usr/lib/go/src/pkg/runtime/panic.c:279 +0xe9 sync/atomic.AddUint64(0x183000e9, 0xffffffff, 0xffffffff, 0x1, 0x1) /usr/lib/go/src/pkg/sync/atomic/asm_386.s:118 +0xc main.main() /root/14.go:33 +0x21a
goroutine 17 [runnable]: runtime.MHeap_Scavenger() /usr/lib/go/src/pkg/runtime/mheap.c:507 runtime.goexit() /usr/lib/go/src/pkg/runtime/proc.c:1445
goroutine 18 [runnable]: bgsweep() /usr/lib/go/src/pkg/runtime/mgc0.c:1976 runtime.goexit() /usr/lib/go/src/pkg/runtime/proc.c:1445
goroutine 19 [runnable]: runfinq() /usr/lib/go/src/pkg/runtime/mgc0.c:2606 runtime.goexit() /usr/lib/go/src/pkg/runtime/proc.c:1445 exit status 2
### 4.1 举例
// A WaitGroup waits for a collection of goroutines to finish.
// The main goroutine calls Add to set the number of
// goroutines to wait for. Then each of the goroutines
// runs and calls Done when finished. At the same time,
// Wait can be used to block until all goroutines have finished.
//
// A WaitGroup must not be copied after first use.
type WaitGroup struct {
noCopy noCopy
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers do not ensure it. So we allocate 12 bytes and then use
// the aligned 8 bytes in them as state, and the other 4 as storage
// for the sema.
state1 [3]uint32
//64位值:高32位为计数器,低32位为服务员计数。
//64位原子操作需要64位对齐,但32位编译器无法确保对齐。
//因此,我们分配了12个字节,然后使用其中对齐的8个字节作为状态,其他4个字节作为sema的存储。
}
// state returns pointers to the state and sema fields stored within wg.state1.
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
// 判断地址是否8位对齐
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
// 前 8 bytes 作 uint64 指针 statep ,后 4 bytes 作 semap
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
} else {
// 否则相反
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
}
}
### 4.2 64位字的安全访问保证(32位系统)
在x86-32上,64位函数使用Pentium MMX之前不存在的指令。
在非Linux ARM上,64位函数使用ARMv6k内核之前不可用的指令。
在ARM,x86-32和32位MIPS上,调用方有责任安排对原子访问的64位字的64位对齐。 变量或分配的结构、数组或切片中的第一个字( word)可以依赖当做是64位对齐的。
### 4.3 64位字的安全访问保证 Why?
这是因为int64在bool之后未对齐。
它是32位对齐的,但不是64位对齐的,因为我们使用的是32位系统,
因此实际上只是两个32位值并排在一起。
https://github.com/golang/go/issues/6404#issuecomment-66085602
type WillPanic struct {
init bool
uncounted int64
}
### 4.4 64位字的安全访问保证 How?
变量或已分配的结构体、数组或切片中的第一个字( word)可以依赖当做是64位对齐的。
The first word in a variable or in an allocated struct, array, or slice can be relied upon to be 64-bit aligned.
//切片会内存对齐,因为切片实际上在结构体中是指向另一块内存的指针,内存地址分布与结构体无关
c5 := struct {
val int64
valid bool
val2 []int64
}{val2: []int64{0}}
fmt.Println("结构体中的64位字切片:", atomic.AddInt64(&c5.val2[0], 1))
//数组不会内存对齐,因为数组的内存与结构体存放在一起,所以会收到结构体影响
c6 := struct {
val int64
valid bool
val2 [3]int64
}{val2: [3]int64{0}}
fmt.Println("结构体中的64位字数组:", atomic.AddInt64(&c6.val2[0], 1))
### 4.5 一些源码中的例子
GMP中的管理groutine本地队列的上下文p中,记录计时器运行时长的uint64, 需要保证32位系统上也是8byte对齐(原子操作)
// runtime.runtime2.go
type p struct {
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
pcache pageCache
raceprocctx uintptr
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
// Cache of mspan objects from the heap.
mspancache struct {
// We need an explicit length here because this field is used
// in allocation codepaths where write barriers are not allowed,
// and eliminating the write barrier/keeping it eliminated from
// slice updates is tricky, moreso than just managing the length
// ourselves.
len int
buf [128]*mspan
}
tracebuf traceBufPtr
// traceSweep indicates the sweep events should be traced.
// This is used to defer the sweep start event until a span
// has actually been swept.
traceSweep bool
// traceSwept and traceReclaimed track the number of bytes
// swept and reclaimed by sweeping in the current sweep loop.
traceSwept, traceReclaimed uintptr
palloc persistentAlloc // per-P to avoid mutex
_ uint32 // Alignment for atomic fields below
// The when field of the first entry on the timer heap.
// This is updated using atomic functions.
// This is 0 if the timer heap is empty.
timer0When uint64
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)
gcBgMarkWorker guintptr // (atomic)
gcMarkWorkerMode gcMarkWorkerMode
// gcMarkWorkerStartTime is the nanotime() at which this mark
// worker started.
gcMarkWorkerStartTime int64
// gcw is this P's GC work buffer cache. The work buffer is
// filled by write barriers, drained by mutator assists, and
// disposed on certain GC state transitions.
gcw gcWork
// wbBuf is this P's GC write barrier buffer.
//
// TODO: Consider caching this in the running G.
wbBuf wbBuf
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
// Lock for timers. We normally access the timers while running
// on this P, but the scheduler can also do it from a different P.
timersLock mutex
// Actions to take at some time. This is used to implement the
// standard library's time package.
// Must hold timersLock to access.
timers []*timer
// Number of timers in P's heap.
// Modified using atomic instructions.
numTimers uint32
// Number of timerModifiedEarlier timers on P's heap.
// This should only be modified while holding timersLock,
// or while the timer status is in a transient state
// such as timerModifying.
adjustTimers uint32
// Number of timerDeleted timers in P's heap.
// Modified using atomic instructions.
deletedTimers uint32
// Race context used while executing timer functions.
timerRaceCtx uintptr
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
pad cpu.CacheLinePad
}
堆对象分配的mheap中,管理全局cache的中心缓存列表central,分配或释放需要加互斥锁 另外为了不同列表间互斥锁不会伪共享,增加了cacheLinePadding
cacheLine 参考: https://appliedgo.net/concurrencyslower/
// runtime/mheap.go
// Main malloc heap.
// The heap itself is the "free" and "scav" treaps,
// but all the other global data is here too.
//
// mheap must not be heap-allocated because it contains mSpanLists,
// which must not be heap-allocated.
//
//go:notinheap
type mheap struct {
// lock must only be acquired on the system stack, otherwise a g
// could self-deadlock if its stack grows with the lock held.
lock mutex
pages pageAlloc // page allocation data structure
sweepgen uint32 // sweep generation, see comment in mspan; written during STW
sweepdone uint32 // all spans are swept
sweepers uint32 // number of active sweepone calls
// allspans is a slice of all mspans ever created. Each mspan
// appears exactly once.
//
// The memory for allspans is manually managed and can be
// reallocated and move as the heap grows.
//
// In general, allspans is protected by mheap_.lock, which
// prevents concurrent access as well as freeing the backing
// store. Accesses during STW might not hold the lock, but
// must ensure that allocation cannot happen around the
// access (since that may free the backing store).
allspans []*mspan // all spans out there
// sweepSpans contains two mspan stacks: one of swept in-use
// spans, and one of unswept in-use spans. These two trade
// roles on each GC cycle. Since the sweepgen increases by 2
// on each cycle, this means the swept spans are in
// sweepSpans[sweepgen/2%2] and the unswept spans are in
// sweepSpans[1-sweepgen/2%2]. Sweeping pops spans from the
// unswept stack and pushes spans that are still in-use on the
// swept stack. Likewise, allocating an in-use span pushes it
// on the swept stack.
sweepSpans [2]gcSweepBuf
// _ uint32 // align uint64 fields on 32-bit for atomics
// Proportional sweep
//
// These parameters represent a linear function from heap_live
// to page sweep count. The proportional sweep system works to
// stay in the black by keeping the current page sweep count
// above this line at the current heap_live.
//
// The line has slope sweepPagesPerByte and passes through a
// basis point at (sweepHeapLiveBasis, pagesSweptBasis). At
// any given time, the system is at (memstats.heap_live,
// pagesSwept) in this space.
//
// It's important that the line pass through a point we
// control rather than simply starting at a (0,0) origin
// because that lets us adjust sweep pacing at any time while
// accounting for current progress. If we could only adjust
// the slope, it would create a discontinuity in debt if any
// progress has already been made.
pagesInUse uint64 // pages of spans in stats mSpanInUse; updated atomically
pagesSwept uint64 // pages swept this cycle; updated atomically
pagesSweptBasis uint64 // pagesSwept to use as the origin of the sweep ratio; updated atomically
sweepHeapLiveBasis uint64 // value of heap_live to use as the origin of sweep ratio; written with lock, read without
sweepPagesPerByte float64 // proportional sweep ratio; written with lock, read without
// TODO(austin): pagesInUse should be a uintptr, but the 386
// compiler can't 8-byte align fields.
// scavengeGoal is the amount of total retained heap memory (measured by
// heapRetained) that the runtime will try to maintain by returning memory
// to the OS.
scavengeGoal uint64
// Page reclaimer state
// reclaimIndex is the page index in allArenas of next page to
// reclaim. Specifically, it refers to page (i %
// pagesPerArena) of arena allArenas[i / pagesPerArena].
//
// If this is >= 1<<63, the page reclaimer is done scanning
// the page marks.
//
// This is accessed atomically.
reclaimIndex uint64
// reclaimCredit is spare credit for extra pages swept. Since
// the page reclaimer works in large chunks, it may reclaim
// more than requested. Any spare pages released go to this
// credit pool.
//
// This is accessed atomically.
reclaimCredit uintptr
// Malloc stats.
largealloc uint64 // bytes allocated for large objects
nlargealloc uint64 // number of large object allocations
largefree uint64 // bytes freed for large objects (>maxsmallsize)
nlargefree uint64 // number of frees for large objects (>maxsmallsize)
nsmallfree [_NumSizeClasses]uint64 // number of frees for small objects (<=maxsmallsize)
// arenas is the heap arena map. It points to the metadata for
// the heap for every arena frame of the entire usable virtual
// address space.
//
// Use arenaIndex to compute indexes into this array.
//
// For regions of the address space that are not backed by the
// Go heap, the arena map contains nil.
//
// Modifications are protected by mheap_.lock. Reads can be
// performed without locking; however, a given entry can
// transition from nil to non-nil at any time when the lock
// isn't held. (Entries never transitions back to nil.)
//
// In general, this is a two-level mapping consisting of an L1
// map and possibly many L2 maps. This saves space when there
// are a huge number of arena frames. However, on many
// platforms (even 64-bit), arenaL1Bits is 0, making this
// effectively a single-level map. In this case, arenas[0]
// will never be nil.
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
// heapArenaAlloc is pre-reserved space for allocating heapArena
// objects. This is only used on 32-bit, where we pre-reserve
// this space to avoid interleaving it with the heap itself.
heapArenaAlloc linearAlloc
// arenaHints is a list of addresses at which to attempt to
// add more heap arenas. This is initially populated with a
// set of general hint addresses, and grown with the bounds of
// actual heap arena ranges.
arenaHints *arenaHint
// arena is a pre-reserved space for allocating heap arenas
// (the actual arenas). This is only used on 32-bit.
arena linearAlloc
// allArenas is the arenaIndex of every mapped arena. This can
// be used to iterate through the address space.
//
// Access is protected by mheap_.lock. However, since this is
// append-only and old backing arrays are never freed, it is
// safe to acquire mheap_.lock, copy the slice header, and
// then release mheap_.lock.
allArenas []arenaIdx
// sweepArenas is a snapshot of allArenas taken at the
// beginning of the sweep cycle. This can be read safely by
// simply blocking GC (by disabling preemption).
sweepArenas []arenaIdx
// curArena is the arena that the heap is currently growing
// into. This should always be physPageSize-aligned.
curArena struct {
base, end uintptr
}
_ uint32 // ensure 64-bit alignment of central
// central free lists for small size classes.
// the padding makes sure that the mcentrals are
// spaced CacheLinePadSize bytes apart, so that each mcentral.lock
// gets its own cache line.
// central is indexed by spanClass.
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
specialprofilealloc fixalloc // allocator for specialprofile*
speciallock mutex // lock for special record allocators.
arenaHintAlloc fixalloc // allocator for arenaHints
unused *specialfinalizer // never set, just here to force the specialfinalizer type into DWARF
}
### 4.6 64位字的安全访问保证 (Bug!)
如果包含首个64位字的结构体是12byte大小 时,不一定能保证64未对齐
这是因为tinyalloc分配小对象时没有做对齐保证
https://github.com/golang/go/issues/37262#issuecomment-587576192
//runtime/malloc.go
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if debug.sbrk != 0 {
align := uintptr(16)
if typ != nil {
// TODO(austin): This should be just
// align = uintptr(typ.align)
// but that's only 4 on 32-bit platforms,
// even if there's a uint64 field in typ (see #599).
// This causes 64-bit atomic accesses to panic.
// Hence, we use stricter alignment that matches
// the normal allocator better.
if size&7 == 0 {
align = 8
} else if size&3 == 0 {
align = 4
} else if size&1 == 0 {
align = 2
} else {
align = 1
}
}
return persistentalloc(size, align, &memstats.other_sys)
}
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := size
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.ptrdata == 0
if size <= maxSmallSize {
if noscan && size < maxTinySize {
// Tiny allocator.
//
// Tiny allocator combines several tiny allocation requests
// into a single memory block. The resulting memory block
// is freed when all subobjects are unreachable. The subobjects
// must be noscan (don't have pointers), this ensures that
// the amount of potentially wasted memory is bounded.
//
// Size of the memory block used for combining (maxTinySize) is tunable.
// Current setting is 16 bytes, which relates to 2x worst case memory
// wastage (when all but one subobjects are unreachable).
// 8 bytes would result in no wastage at all, but provides less
// opportunities for combining.
// 32 bytes provides more opportunities for combining,
// but can lead to 4x worst case wastage.
// The best case winning is 8x regardless of block size.
//
// Objects obtained from tiny allocator must not be freed explicitly.
// So when an object will be freed explicitly, we ensure that
// its size >= maxTinySize.
//
// SetFinalizer has a special case for objects potentially coming
// from tiny allocator, it such case it allows to set finalizers
// for an inner byte of a memory block.
//
// The main targets of tiny allocator are small strings and
// standalone escaping variables. On a json benchmark
// the allocator reduces number of allocations by ~12% and
// reduces heap size by ~20%.
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
if size&7 == 0 {
off = alignUp(off, 8)
} else if size&3 == 0 {
off = alignUp(off, 4)
} else if size&1 == 0 {
off = alignUp(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
// The object fits into existing tiny block.
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
span := c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else {
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
span := c.alloc[spc]
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else {
var s *mspan
shouldhelpgc = true
systemstack(func() {
s = largeAlloc(size, needzero, noscan)
})
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
publicationBarrier()
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0
releasem(mp)
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
if rate := MemProfileRate; rate > 0 {
if rate != 1 && size < c.next_sample {
c.next_sample -= size
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t)
}
}
return x
}
### 4.7 64位字的安全访问保证 (改为加锁!)
c := struct {
val int16
val2 int64
}{}
var mutex sync.Mutex
mutex.Lock()
c.val2 += 1
mutex.Unlock()
## 5. 总结
好好学习,天天向上