
在实现需求的过程中, 经常会遇到如下的一类需求:
使用定时器可以方便的实现上述功能. 定时器是一种结构, 它的主要作用是在一个给定的时间间隔之后, 调用一个给定的回调函数或者发出一个信号, 应用可以在回调函数或信号处理函数中实现相应的业务逻辑.
在 Go 中, 标准库 time 包提供了一些基本的定时器相关操作, 常见的用法如下:
func delayOnce() {
n := time.Now()
fmt.Println("delayOnce start, ", n)
// delay 1 second
<-time.After(time.Second)
fmt.Println("Cost ", time.Since(n))
}
func delayTicker() {
n := time.Now()
fmt.Println("delayTicker start, ", n)
// ticker 1 second, 3 times
t := time.NewTicker(time.Second)
for i := 0; i < 3; i++ {
<-t.C
fmt.Println("Tick ", time.Since(n))
}
t.Stop()
fmt.Println("Cost ", time.Since(n))
}
可以看到, 有几种方式来使用定时器:
上述三种都是一次性的定时器, 还有一种持续性的定时器(ticker):
跟golang定时器相关的入口主要有以下几种方法:
<-time.Tick(time.Second)
<-time.After(time.Second)
<-time.NewTicker(time.Second).C
<-time.NewTimer(time.Second).C
time.AfterFunc(time.Second, func() { /*do*/ })
time.Sleep(time.Second)
这里我们以其中NewTicker为入口,NewTicker的源码如下:
func NewTicker(d Duration) *Ticker {
if d <= 0 {
panic(errors.New("non-positive interval for NewTicker"))
}
c := make(chan Time, 1)
t := &Ticker{
C: c,
r: runtimeTimer{
// when(d)返回一个runtimeNano() + int64(d)的未来时(到期时间)
//runtimeNano运行时当前纳秒时间
when: when(d),
period: int64(d), // 被唤醒的时间
f: sendTime, // 时间到期后的回调函数
arg: c, // 时间到期后的断言参数
},
}
// 将新的定时任务添加到时间堆中
// 编译器会将这个函数翻译为runtime.startTimer(t *runtime.timer)
// time.runtimeTimer翻译为runtime.timer
startTimer(&t.r)
return t
}
这里有个比较重要的是startTimer(&t.r)它的实现被翻译在runtime包内
func startTimer(t *timer) {
if raceenabled {
racerelease(unsafe.Pointer(t))
}
addtimer(t)
}
func addtimer(t *timer) {
lock(&timers.lock)
addtimerLocked(t)
unlock(&timers.lock)
}
上面的代码为了看着方便,我将他们都放在一起
下面代码都写出部分注释
// 使用锁将计时器添加到堆中
// 如果是第一次运行此方法则启动timerproc
func addtimerLocked(t *timer) {
if t.when < 0 {
t.when = 1<<63 - 1
}
// t.i i是定时任务数组中的索引
// 将新的定时任务追加到定时任务数组队尾
t.i = len(timers.t)
timers.t = append(timers.t, t)
// 使用数组实现的四叉树最小堆根据when(到期时间)进行排序
siftupTimer(t.i)
// 如果t.i 索引为0
if t.i == 0 {
if timers.sleeping {
// 如果还在sleep就唤醒
timers.sleeping = false
// 这里基于OS的同步,并进行OS系统调用
// 在timerproc()使goroutine从睡眠状态恢复
notewakeup(&timers.waitnote)
}
if timers.rescheduling {
timers.rescheduling = false
// 如果没有定时器,timerproc()与goparkunlock共同sleep
// goready这里特殊说明下,在线程创建的堆栈,它比goroutine堆栈大。
// 函数不能增长堆栈,同时不能被调度器抢占
goready(timers.gp, 0)
}
}
if !timers.created {
timers.created = true
go timerproc() //这里只有初始化一次
}
}
// Timerproc运行时间驱动的事件。
// 它sleep到计时器堆中的下一个。
// 如果addtimer插入一个新的事件,它会提前唤醒timerproc。
func timerproc() {
timers.gp = getg()
for {
lock(&timers.lock)
timers.sleeping = false
now := nanotime()
delta := int64(-1)
for {
if len(timers.t) == 0 {
delta = -1
break
}
t := timers.t[0]
delta = t.when - now
if delta > 0 {
break // 时间未到
}
if t.period > 0 {
// 计算下一次时间
// period被唤醒的间隔
t.when += t.period * (1 + -delta/t.period)
siftdownTimer(0)
} else {
// remove from heap
last := len(timers.t) - 1
if last > 0 {
timers.t[0] = timers.t[last]
timers.t[0].i = 0
}
timers.t[last] = nil
timers.t = timers.t[:last]
if last > 0 {
siftdownTimer(0)
}
t.i = -1 // 标记移除
}
f := t.f
arg := t.arg
seq := t.seq
unlock(&timers.lock)
if raceenabled {
raceacquire(unsafe.Pointer(t))
}
f(arg, seq)
lock(&timers.lock)
}
if delta < 0 || faketime > 0 {
// 没有定时器,把goroutine sleep。
timers.rescheduling = true
// 将当前的goroutine放入等待状态并解锁锁。
// goroutine也可以通过呼叫goready(gp)来重新运行。
goparkunlock(&timers.lock, "timer goroutine (idle)", traceEvGoBlock, 1)
continue
}
// At least one timer pending. Sleep until then.
timers.sleeping = true
timers.sleepUntil = now + delta
// 重置
noteclear(&timers.waitnote)
unlock(&timers.lock)
// 使goroutine进入睡眠状态,直到notewakeup被调用,
// 通过notewakeup 唤醒
notetsleepg(&timers.waitnote, delta)
}
}
golang使用最小堆(最小堆是满足除了根节点以外的每个节点都不小于其父节点的堆)实现的定时器。golang []*****timer结构如下:
 golang存储定时任务结构
golang存储定时任务结构
addtimer在堆中插入一个值,然后保持最小堆的特性,其实这个结构本质就是最小优先队列的一个应用,然后将时间转换一个绝对时间处理,通过睡眠和唤醒找出定时任务,这里阅读起来源码很容易,所以只将代码和部分注释写出。
例如, 服务器维护有对客户端的连接, 并且定时在连接中发送心跳来确保连接的可用性, 一个普遍的实现方式如下:
func onConnect(ctx context.Context, i int) {
t := time.NewTicker(time.Second)
n := time.Now()
for {
select {
case <-ctx.Done():
fmt.Println("Done")
return
case <-t.C:
fmt.Printf("Tick[%v] %v\n", i, time.Since(n))
}
}
}
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
for i := 0; i < 10; i++ {
go onConnect(ctx, i)
}
<-ctx.Done()
time.Sleep(time.Second) // wait all sub goroutine exit, should use WaitGroup
}
但是这种方式中, 每一个连接就需要新增一个 goroutine, 并且对 goroutine 的清理也会比较复杂. 所以, 如果有一个独立的 goroutine 能够对这些定时任务进行触发, 操作上会方便很多.
一个时间轮就是一个定时器容器, 该容器可以高效的管理定时器. 思路如下:
整个定时器只有一个表盘,用循环数组代表表盘,每个槽的时间间隔(tick)代表了定时器能够达到的定时精度,循环数组的大小代表了整个定时器可以定时的时间范围。比如说要一个可以最大定时一分钟的时间轮,其表盘分为60个槽,每隔1秒钟(tick),指针转动一个槽.netty中就使用了这类结构实现时间轮。 单表盘时间轮的好处是实现简单,定时精确,但是也有个问题是所能代表的时间有限。设想一下如果要表示一个计时范围1小时,精度1秒的时间轮,那么循环数组的大小就需要3600,如果标识一天呢,就需要3600*24.
如果任务不只限定在一天之内呢?比如我有个任务,需要每周一上午九点执行,我还有另一个任务,需要每周三的上午九点执行。一种很容易想到的解决办法是:
增大时间轮的刻度
一天24个小时,一周168个小时,为了解决上面的问题,我可以把时间轮的刻度(槽)从12个增加到168个,比如现在是星期二上午10点钟,那么下周一上午九点就是时间轮的第9个刻度,这周三上午九点就是时间轮的第57个刻度,示意图如下:
仔细思考一下,会发现这中方式存在几个缺陷:
这次我不增加时间轮的刻度了,现在有三个任务需要执行,
比如现在是9月11号星期二上午10点,时间轮转一圈是24小时,
任务一下次执行(下周二上午九点),需要时间轮转过6圈后,到第7圈的第9个刻度开始执行。
任务二下次执行第3圈的第9个刻度,任务三是第2圈的第9个刻度。
示意图如下:
时间轮每移动到一个刻度时,遍历任务列表,把round值-1,然后取出所有round=0的任务执行。
这样做能解决时间轮刻度范围过大造成的空间浪费,但是却带来了另一个问题:时间轮每次都需要遍历任务列表,耗时增加,当时间轮刻度粒度很小(秒级甚至毫秒级),任务列表又特别长时,这种遍历的办法是不可接受的。
当然,对于大多数场景,这种方法还是适用的。有没有既节省空间,又节省时间的办法呢?
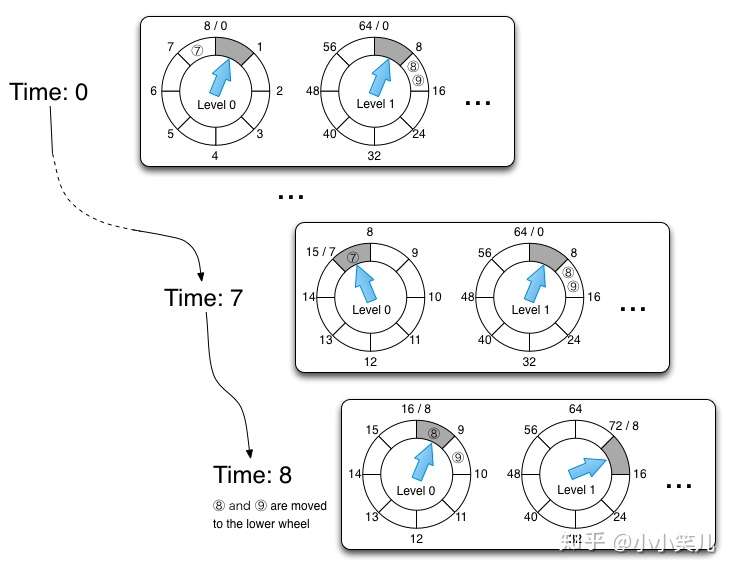
在层级时间轮中, 将插槽分为多个层次, 每一层的时间轮的插槽范围都会扩大, 例如:
第一层时间轮有20个插槽, 每个插槽为1秒, 那么第二层时间轮每个插槽为20秒, 第三层为400秒, 依次类推, 除第一层外都是按需创建
当一个10秒的定时器插入时放置到第一层时间轮中, 100秒的定时器则放置到第二层时间轮
随着时间的流逝, 高层时间轮中的定时任务会降级重新插入低层的时间轮, 直到触发为止
每个插槽共享一个触发时间, 这样可以显著降低需要触发的事件的个数
一个示意图如下:
好好学习,天天向上