
现代操作系统都是采用虚拟存储器,那么对 32 位操作系统而言,它的寻址空间(虚拟存储空间)为 4G(2 的 32 次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对 Linux 操作系统而言,将最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF),供内核使用,称为内核空间,而将较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF),供各个进程使用,称为用户空间。
每个进程的 4G 地址空间中,最高 1G 都是一样的,即内核空间。只有剩余的 3G 才归进程自己使用。 换句话说就是, 最高 1G 的内核空间是被所有进程共享的!
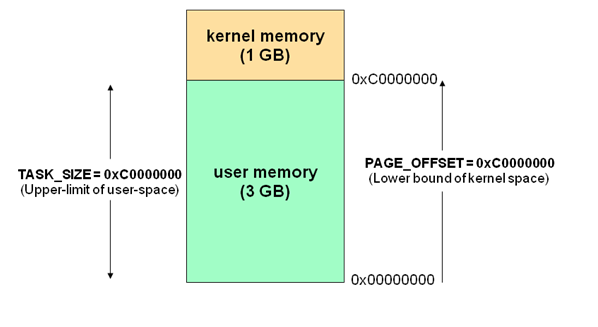
当进程运行在内核空间时就处于内核态,而进程运行在用户空间时则处于用户态。
在内核态下,进程运行在内核地址空间中,此时 CPU 可以执行任何指令。运行的代码也不受任何的限制,可以自由地访问任何有效地址,也可以直接进行端口的访问。 在用户态下,进程运行在用户地址空间中,被执行的代码要受到 CPU 的诸多检查,它们只能访问映射其地址空间的页表项中规定的在用户态下可访问页面的虚拟地址,且只能对任务状态段(TSS)中 I/O 许可位图(I/O Permission Bitmap)中规定的可访问端口进行直接访问。
对于以前的 DOS 操作系统来说,是没有内核空间、用户空间以及内核态、用户态这些概念的。可以认为所有的代码都是运行在内核态的,因而用户编写的应用程序代码可以很容易的让操作系统崩溃掉。 对于 Linux 来说,通过区分内核空间和用户空间的设计,隔离了操作系统代码(操作系统的代码要比应用程序的代码健壮很多)与应用程序代码。即便是单个应用程序出现错误也不会影响到操作系统的稳定性,这样其它的程序还可以正常的运行。
所以,区分内核空间和用户空间本质上是要提高操作系统的稳定性及可用性。
其实所有的系统资源管理都是在内核空间中完成的。比如读写磁盘文件,分配回收内存,从网络接口读写数据等等。我们的应用程序是无法直接进行这样的操作的。但是我们可以通过内核提供的接口来完成这样的任务。 比如应用程序要读取磁盘上的一个文件,它可以向内核发起一个 “系统调用” 告诉内核:”我要读取磁盘上的某某文件”。其实就是通过一个特殊的指令让进程从用户态进入到内核态(到了内核空间),在内核空间中,CPU 可以执行任何的指令,当然也包括从磁盘上读取数据。具体过程是先把数据读取到内核空间中,然后再把数据拷贝到用户空间并从内核态切换到用户态。此时应用程序已经从系统调用中返回并且拿到了想要的数据,可以开开心心的往下执行了。 简单说就是应用程序把高科技的事情(从磁盘读取文件)外包给了系统内核,系统内核做这些事情既专业又高效。
对于一个进程来讲,从用户空间进入内核空间并最终返回到用户空间,这个过程是十分复杂的。举个例子,比如我们经常接触的概念 “堆栈”,其实进程在内核态和用户态各有一个堆栈。运行在用户空间时进程使用的是用户空间中的堆栈,而运行在内核空间时,进程使用的是内核空间中的堆栈。所以说,Linux 中每个进程有两个栈,分别用于用户态和内核态。
下图简明的描述了用户态与内核态之间的转换:
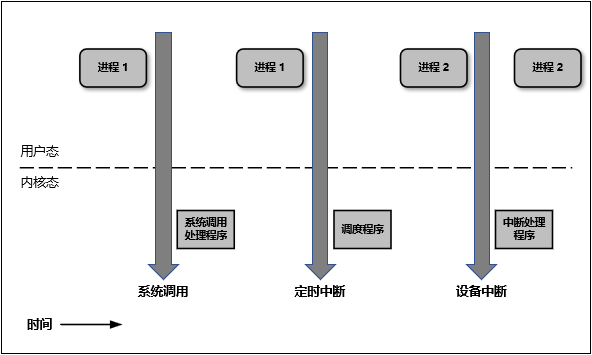
既然用户态的进程必须切换成内核态才能使用系统的资源,那么我们接下来就看看进程一共有多少种方式可以从用户态进入到内核态。概括的说,有三种方式:系统调用、软中断和硬件中断。这三种方式每一种都涉及到大量的操作系统知识,所以这里不做展开。
《UNIX 网络编程》里,总结归纳了 5 种 I/O 模型,包括同步和异步 I/O:
操作系统上的 I/O 是 用户空间 和 内核空间 的数据交互,因此 I/O 操作通常包含以下两个步骤:
而判定一个 I/O 模型是同步还是异步,主要看第二步:数据在用户和内核空间之间复制的时候是不是会阻塞当前进程,如果会,则是同步 I/O,否则,就是异步 I/O。
各种IO模型的优缺点:
所谓 I/O 多路复用指的就是 select/poll/epoll 这一系列的多路选择器:支持单一线程同时监听多个文件描述符(I/O 事件),阻塞等待,并在其中某个文件描述符可读写时收到通知。 I/O 复用其实复用的不是 I/O 连接,而是复用线程,让一个 thread of control 能够处理多个连接(I/O 事件)
#include <sys/select.h>
/* According to earlier standards */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
// 和 select 紧密结合的四个宏:
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
select 是 epoll 之前 Linux 使用的 I/O 事件驱动技术。
理解 select 的关键在于理解 fd_set,为说明方便,取 fd_set 长度为 1 字节,fd_set 中的每一 bit 可以对应一个文件描述符 fd,则 1 字节长的 fd_set 最大可以对应 8 个 fd。select 的调用过程如下:
0000,00000001,00110000,0011 (注意:没有事件发生的 fd=5 被清空)基于上面的调用过程,可以得出 select 的特点:
所以,select 有如下的缺点:
poll 的实现和 select 非常相似,只是描述 fd 集合的方式不同,poll 使用 pollfd 结构而不是 select 的 fd_set 结构,poll 解决了最大文件描述符数量限制的问题,但是同样需要从用户态拷贝所有的 fd 到内核态,也需要线性遍历所有的 fd 集合,所以它和 select 只是实现细节上的区分,并没有本质上的区别。
epoll 是 Linux kernel 2.6 之后引入的新 I/O 事件驱动技术
I/O 多路复用的核心设计是 1 个线程处理所有连接的 等待消息准备好 I/O 事件,这一点上 epoll 和 select&poll 是大同小异的。但 select&poll 错误预估了一件事,当数十万并发连接存在时,可能每一毫秒只有数百个活跃的连接,同时其余数十万连接在这一毫秒是非活跃的。select&poll 的使用方法是这样的: 返回的活跃连接 == select(全部待监控的连接) 。
什么时候会调用 select&poll 呢?在你认为需要找出有报文到达的活跃连接时,就应该调用。所以,select&poll 在高并发时是会被频繁调用的。这样,这个频繁调用的方法就很有必要看看它是否有效率,因为,它的轻微效率损失都会被 高频 二字所放大。它有效率损失吗?显而易见,全部待监控连接是数以十万计的,返回的只是数百个活跃连接,这本身就是无效率的表现。被放大后就会发现,处理并发上万个连接时,select&poll 就完全力不从心了。这个时候就该 epoll 上场了,epoll 通过一些新的设计和优化,基本上解决了 select&poll 的问题。
epoll 的 API 非常简洁,涉及到的只有 3 个系统调用:
#include <sys/epoll.h>
int epoll_create(int size); // 创建一个 epoll
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 监听文件描述符的io事件,添加、修改文件描述符的监听事件
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);// 等待 监听的文件描述符集合 出现 io 事件
// 获取一个新连接
func (fd *netFD) accept() (netfd *netFD, err error) {
// 获取一个 文件描述符
d, rsa, errcall, err := fd.pfd.Accept()
if err != nil {
if errcall != "" {
err = wrapSyscallError(errcall, err)
}
return nil, err
}
// 构建 连接的 NETFD 用于连接读
if netfd, err = newFD(d, fd.family, fd.sotype, fd.net); err != nil {
poll.CloseFunc(d)
return nil, err
}
if err = netfd.init(); err != nil {
netfd.Close()
return nil, err
}
lsa, _ := syscall.Getsockname(netfd.pfd.Sysfd)
netfd.setAddr(netfd.addrFunc()(lsa), netfd.addrFunc()(rsa))
return netfd, nil
}
// Accept wraps the accept network call.
func (fd *FD) Accept() (int, syscall.Sockaddr, string, error) {
if err := fd.readLock(); err != nil {
return -1, nil, "", err
}
defer fd.readUnlock()
if err := fd.pd.prepareRead(fd.isFile); err != nil {
return -1, nil, "", err
}
for {
// 触发一次系统调用,获取 socket
s, rsa, errcall, err := accept(fd.Sysfd)
if err == nil {
return s, rsa, "", err
}
switch err {
case syscall.EINTR:
continue
case syscall.EAGAIN:
// 如果这时 socket 还不可读,则 park 当前 goroutine
if fd.pd.pollable() {
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
}
case syscall.ECONNABORTED:
// This means that a socket on the listen
// queue was closed before we Accept()ed it;
// it's a silly error, so try again.
continue
}
return -1, nil, errcall, err
}
}
// returns true if IO is ready, or false if timedout or closed
// waitio - wait only for completed IO, ignore errors
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
// set the gpp semaphore to pdWait
for {
old := *gpp
if old == pdReady {
*gpp = 0
return true
}
if old != 0 {
throw("runtime: double wait")
}
if atomic.Casuintptr(gpp, 0, pdWait) {
break
}
}
// need to recheck error states after setting gpp to pdWait
// this is necessary because runtime_pollUnblock/runtime_pollSetDeadline/deadlineimpl
// do the opposite: store to closing/rd/wd, membarrier, load of rg/wg
if waitio || netpollcheckerr(pd, mode) == 0 {
// gopark 将当前 goroutine park 住,等待唤醒
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
// be careful to not lose concurrent pdReady notification
old := atomic.Xchguintptr(gpp, 0)
if old > pdWait {
throw("runtime: corrupted polldesc")
}
return old == pdReady
}
// Puts the current goroutine into a waiting state and calls unlockf on the
// system stack.
//
// If unlockf returns false, the goroutine is resumed.
//
// unlockf must not access this G's stack, as it may be moved between
// the call to gopark and the call to unlockf.
//
// Note that because unlockf is called after putting the G into a waiting
// state, the G may have already been readied by the time unlockf is called
// unless there is external synchronization preventing the G from being
// readied. If unlockf returns false, it must guarantee that the G cannot be
// externally readied.
//
// Reason explains why the goroutine has been parked. It is displayed in stack
// traces and heap dumps. Reasons should be unique and descriptive. Do not
// re-use reasons, add new ones.
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
// 获取执行当前 Goroutine 的 M
mp := acquirem()
// 获取此 M 的 Goroutine 也就是当前 Routine
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
// park_m是一个函数指针。mcall在golang需要进行协程切换时被调用,做的主要工作是:
// 切换当前线程的堆栈从g的堆栈切换到g0的堆栈;并在g0的堆栈上执行新的函数fn(g);
// 保存当前协程的信息( PC/SP存储到g->sched),当后续对当前协程调用goready函数时候能够恢复现场;
mcall(park_m)
}
// park continuation on g0.
func park_m(gp *g) {
// 获取当前的 Goroutine (这时是在g0)
_g_ := getg()
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
// 将当前 Goroutine 状态置换成 _Gwaiting
casgstatus(gp, _Grunning, _Gwaiting)
// 移除gp与m的绑定关系
dropg()
if fn := _g_.m.waitunlockf; fn != nil {
ok := fn(gp, _g_.m.waitlock)
_g_.m.waitunlockf = nil
_g_.m.waitlock = nil
if !ok {
if trace.enabled {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
// 进行一次 Goroutine 的调度
schedule()
}
// getg returns the pointer to the current g.
// The compiler rewrites calls to this function into instructions
// that fetch the g directly (from TLS or from the dedicated register).
func getg() *g
至此,goroutine 被成功park住
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
// ...
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
// ...
}
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from local or global queue, poll network.
func findrunnable() (gp *g, inheritTime bool) {
// ...
// Poll network.
// This netpoll is only an optimization before we resort to stealing.
// We can safely skip it if there are no waiters or a thread is blocked
// in netpoll already. If there is any kind of logical race with that
// blocked thread (e.g. it has already returned from netpoll, but does
// not set lastpoll yet), this thread will do blocking netpoll below
// anyway.
// netpoll 里会调用 epoll_wait 从 epoll 的 eventpoll.rdllist 就绪双向链表返回,从而得到 I/O 就绪的 socket fd 列表,并根据取出最初调用 epoll_ctl 时保存的上下文信息,恢复 g。所以执行完netpoll 之后,会返回一个就绪 fd 列表对应的 goroutine 链表,接下来将就绪的 goroutine 通过调用 injectglist 加入到全局调度队列或者 P 的本地调度队列中,启动 M 绑定 P 去执行。
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
// ...
}
// Go runtime 在程序启动的时候会创建一个独立的 M 作为监控线程,叫 sysmon ,这个线程为系统级的 daemon 线程,无需 P 即可运行, sysmon 每 20us~10ms 运行一次。 sysmon 中以轮询的方式执行以下操作
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
func sysmon() {
// ...
// 调用 runtime.netpoll ,从中找出能从网络 I/O 中唤醒的 g 列表,并通过调用 injectglist 把 g 列表放入全局调度队列或者当前 P 本地调度队列等待被执行,
// poll network if not polled for more than 10ms
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(0) // non-blocking - returns list of goroutines
if !list.empty() {
// Need to decrement number of idle locked M's
// (pretending that one more is running) before injectglist.
// Otherwise it can lead to the following situation:
// injectglist grabs all P's but before it starts M's to run the P's,
// another M returns from syscall, finishes running its G,
// observes that there is no work to do and no other running M's
// and reports deadlock.
incidlelocked(-1)
injectglist(&list)
incidlelocked(1)
}
}
// ...
}
graph LR
initListener==>serve==>start==>activateReactors==>|OpenPoller|epoll
epoll==>|注册listen fd 的 read 事件|accept
graph LR
epoll==>|出现 READ 事件|accept==>newTCPConn
accept==>srv==>|分配|subepoll
newTCPConn==>|注册 accept fd 的 read 事件|handleEvents==>subepoll
graph LR
subepoll==>handleEvents==>loopRead
loopRead==>|CopyFromSocket|inboundBuffer===>|decode packet|reactHandler
由loopRead进入核心逻辑,解析器去分包,分出来的包执行 reactor handler
graph LR
reactHandler==>out==>write
write===>eagain{eagain}
eagain==>|NO|ioWrite
eagain==>|YES|buf==>outbuffer
buf==>|register|epoll
epoll===>handleEvent==>loopWrite==>write
注册时,根据特定算法注册进事件循环器。
// loadBalancer is a interface which manipulates the event-loop set.
loadBalancer interface {
register(*eventloop) // 将事件循环器,注册进负载均衡器
next(net.Addr) *eventloop // 根据 addr 获取一个负载均衡器
iterate(func(int, *eventloop) bool) // 遍历负载均衡器集合
len() int // 获取负载均衡器大小
}
将FD的IO事件监听以及回调函数注册进事件循环,事件循环有IO事件发生时,触发对应FD的回调
type eventloop struct {
ln *listener // listener 监听的 pollerfd
idx int // loop index in the server loops list 负载均衡器内的下标
svr *server // server in loop // server 的一个指针
poller *netpoll.Poller // epoll or kqueue // poller 调度器
buffer []byte // read packet buffer whose capacity is set by user, default value is 64KB 缓冲区 用于 udp 连接
connCount int32 // number of active connections in event-loop 事件循环器管理的连接数
udpSockets map[int]*conn // client-side UDP socket map: fd -> conn UDP连接集合
connections map[int]*conn // TCP connection map: fd -> conn TCP连接集合
eventHandler EventHandler // user eventHandler // 处理回调,在各种事件触发时触发的一些回调
}
Poller 是一个基于epoll的io事件监听器,将文件描述符注册进这里,当文件描述符有io事件发生时,会返回对应的文件描述符集合
// Poller represents a poller which is in charge of monitoring file-descriptors.
type Poller struct {
fd int // epoll fd
wfd int // wake fd 唤醒事件循环的fd,用于触发任务队列
wfdBuf []byte // wfd buffer to read packet // wfd 的缓冲区
netpollWakeSig int32 // 激活 epoll 的信号 1 是激活信号
asyncTaskQueue queue.AsyncTaskQueue // queue with low priority 异步队列
priorAsyncTaskQueue queue.AsyncTaskQueue // queue with high priority 高优先级的异步队列
}
type poller interface {
Close() error
UrgentTrigger(fn queue.TaskFunc, arg interface{}) (err error) // 将任务加入高优先级的异步队列
Trigger(fn queue.TaskFunc, arg interface{}) (err error) // 将任务加入异步队列
Polling(callback func(fd int, ev uint32) error) error // 监听已注册的fd,当有io事件的时候,触发传入的回调函数
AddReadWrite(pa *PollAttachment) error
AddRead(pa *PollAttachment) error
AddWrite(pa *PollAttachment) error
ModRead(pa *PollAttachment) error
ModReadWrite(pa *PollAttachment) error
Delete(fd int) error
}
好好学习,天天向上